Serverless GraphQL, a Step Closer to User
GraphQL can be Frontend’s BFF, I mean by BFF is Backend for Frontend. That in turn takes away the user and/or business logic from Frontend when dealing with user experience. But is it worth separating the said logic from Frontend when the BFF server is miles away?
One of the solutions when working on AWS is having a Serverless GraphQL with Lambda@Edge. This will create an instance of the GraphQL application nearer to the requesting user. However, there are limitations in Lambda@Edge and I am going to share here on how I overcame these challenges.
Lambda@Edge is still a Lambda Function
Lambda@Edge is still a Lambda function that is triggered by Cloudfront, a Content Delivery Network (CDN) service. With that, it enables the application to be closer to the user as it will be instantiated in the Regional Edge location. Normally, one can only deploy a Lambda function to a targeted region and that is the advantage of Lambda@Edge.
Check out this documentation for creating a Serverless GraphQL in NestJS: Serverless
Cold Start
Dealing with lambda function, is to make sure the application is quick enough to start up. Starting up means transferring the code to the runtime environment along with its dependency and spinning it up to have a warm working instance. That is what is called the Cold Start. Once an instance is already in the runtime environment, it can stay there for as long as it is kept warm with consistent requests. However, the idle time is not fixed, it could be 5 minutes of idle time before it will be destroyed and it could go up to 60 minutes.
Here is a good article that experiments about updates on the idle time of lambda before it will be destroyed: How long does AWS Lambda keep your idle functions around before a cold start?
To be able to overcome the Cold Start, function should have higher cpu allocation and to have a higher cpu is to increase the memory allocation.
Here is the sample infrastructure code of Lambda@Edge in CDK: lambda@edge declaration
Increasing the memory allocation, the time it took for a cold start decreases dramatically from ~3s to less than 1s!
Lambda Layer
In a lambda function, one can have a layer where it can be a place for the dependency libraries (i.e node_modules). But for Lambda@Edge, this is one of its limitations and to build the GraphQL application is to bundle it accordingly. Luckily, with NestJS, it has a built-in webpack bundler where it just needs to specify the --webpack option.
Unfortunately, by default, the webpack option does not bundle the libraries from node_modules and so it has to have a webpack configuration. To make it more compact and small, one must have a minifier installed as well.
Here is the sample webpack configuration with Terser plugin as minifier: webpack.config.js
From more than 1MB default webpack bundle along with lambda layer to less than 1MB without lambda layer was achieved!
Additionally, Lambda@Edge has a package size limitation of 1MB for viewer events and 50MB for origin events.
Environment Variables
Another thing that one can have in a lambda function is to have environment variables. Unfortunately for Lambda@Edge, it is its limitation. And so, the source code by default is production ready and will only apply the environment variables when running in development or testing mode.
Alternatively, using SSM Parameters as the source of environment variables is possible. The only downside is that one must have a replication mechanism to make these parameters available in other regions where the Lambda@Edge is actively executed. Without having the replication for SSM Parameter, the only way is to get the parameter in a certain region where it is created. But the catch is, it will add up to the latency as the retrieval takes time especially when the region is far from where the function is executed.
Based on the experiment I did, SSM Parameter located at the us-east-1 region and the Lambda@Edge is at eu-central-1 took ~2.5s, leading to a longer cold start unfortunately. This will be one area to explore on later for improvement.
Persistence Caching
One of the features in GraphQL is Automatic Persisted Query (APQ), where it stores the queries that the client side has with a matching hash code value. This in turns allows the client to send queries just the hash code without sending the big chunk of query. On the GraphQL side, these APQ are stored in memory by default but since Lambda@Edge will have concurrent instances, this means that it would be better to have a shared in memory storage and somehow persist it at the source. I tried to go for the Redis approach but unfortunately it is not possible to access publicly and it should be accessed via VPC. For Lambda@Edge, configuring VPC for other resources access is not possible as it is one of its limitations.
This is one topic for further improvement later on, to have a customized cache layer.
GraphQL at Lambda@Edge
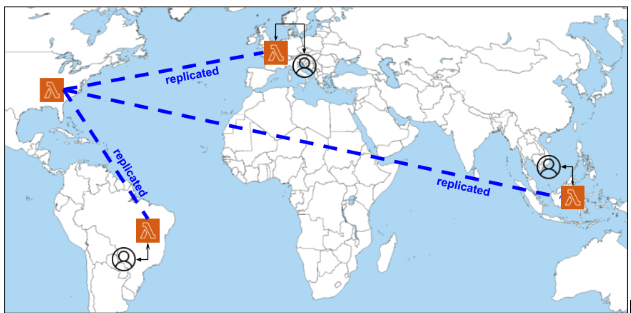
The GraphQL Lambda@Edge needs to be deployed in the us-east-1 (N. Virginia) region. From here, the Serverless GraphQL can be replicated to other regions and this enables the function to be executed in the region near to the user location.
There are 4 events where Lambda@Edge is triggered from Cloudfront:
- Viewer Request
- Viewer Response
- Origin Request
- Origin Response
Normally, the Viewer events are for header and url manipulation and redirection while Origin events are for manipulating data and traffic before and after the origin itself.
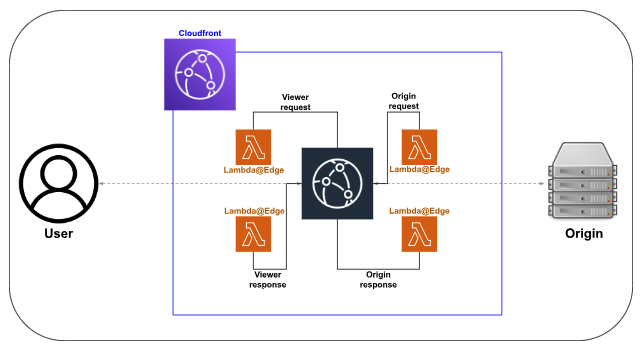
But in the case of the GraphQL application, it only needs the Origin request event. Once the event is received, it will immediately give the response and Cloudfront will respond to the user right away.
So, imagine we have a user in Munich, Germany. The nearest Regional Edge Location is in Frankfurt, Germany. The GraphQL application is deployed in Northern Virginia, United States. Cloudfront is configured that the Origin is the GraphQL application located at N. Virginia, but the Origin Request is the replicated GraphQL in Frankfurt, and so the request flow is just up to Frankfurt and the response will be served to the user.
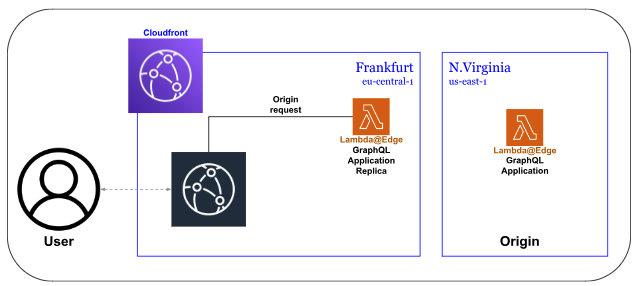
That means the Lambda@Edge in N.Virginia will never be invoked.
Here is the reference to the infrastructure code in CDK of Cloudfront: cloudfront declaration
The Infrastructure
GraphQL as BFF needs to have API calls to gather the data for its business logic. And so, the sample codebase I am going to share contains some Mock APIs as well. In the sample, the Mock APIs are deployed in the eu-west-1 region while the SSM Parameter is in the us-east-1 region.
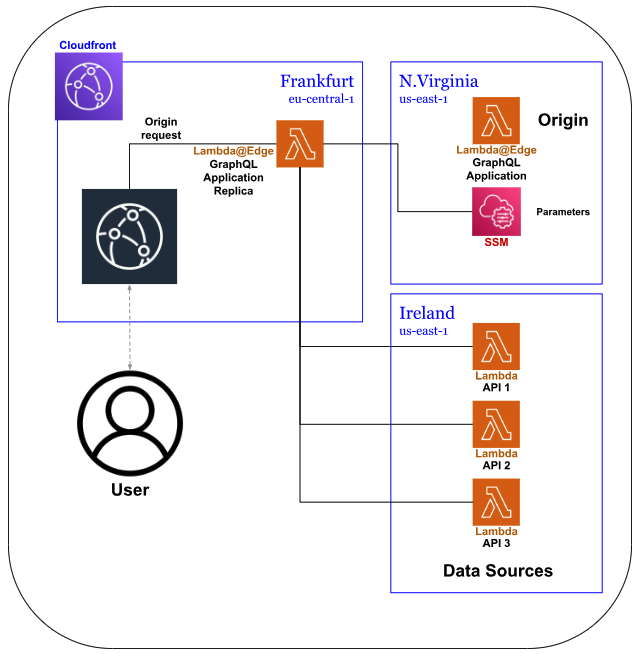
With this infrastructure, with the user located in Frankfurt, the usual process time with a warm lambda took ~200ms. It means that Data Sources calls took most of the time in the process. But in this sample, the data source is quite near to where the user is. It will take longer if the user is quite far from the data source but to think of it, it is the same thing without BFF.
Normally, when having a direct call from Frontend to Data Sources, frontend stores the data in the user’s browser or app. This will eliminate frequent calls to the data sources. The current setup of the GraphQL application in the sample codebase does not have that mechanism and so for further improvement, applying Data Loaders in GraphQL will be explored.
As promised, here is the version of the codebase with the said infrastructure: graphql-as-bff-v1.0.1
Conclusion
It is possible that a GraphQL application as BFF can be nearer to the user with the help of Lambda@Edge. Considering Lambda@Edge limitations, there are still some ways to improve and optimize them.